CC4 - Replicate. Re-create, then improve, someone else's chart.
Task: 1. Find a chart create an image file of their chart.
2. Replicate their chart in Vega-Lite.
3. Improve their chart. Change the elements of the chart specification to make it better
Chart Replication: Gender Distribution by Ethnicity
Source: The Economist
Version 1: Original Chart
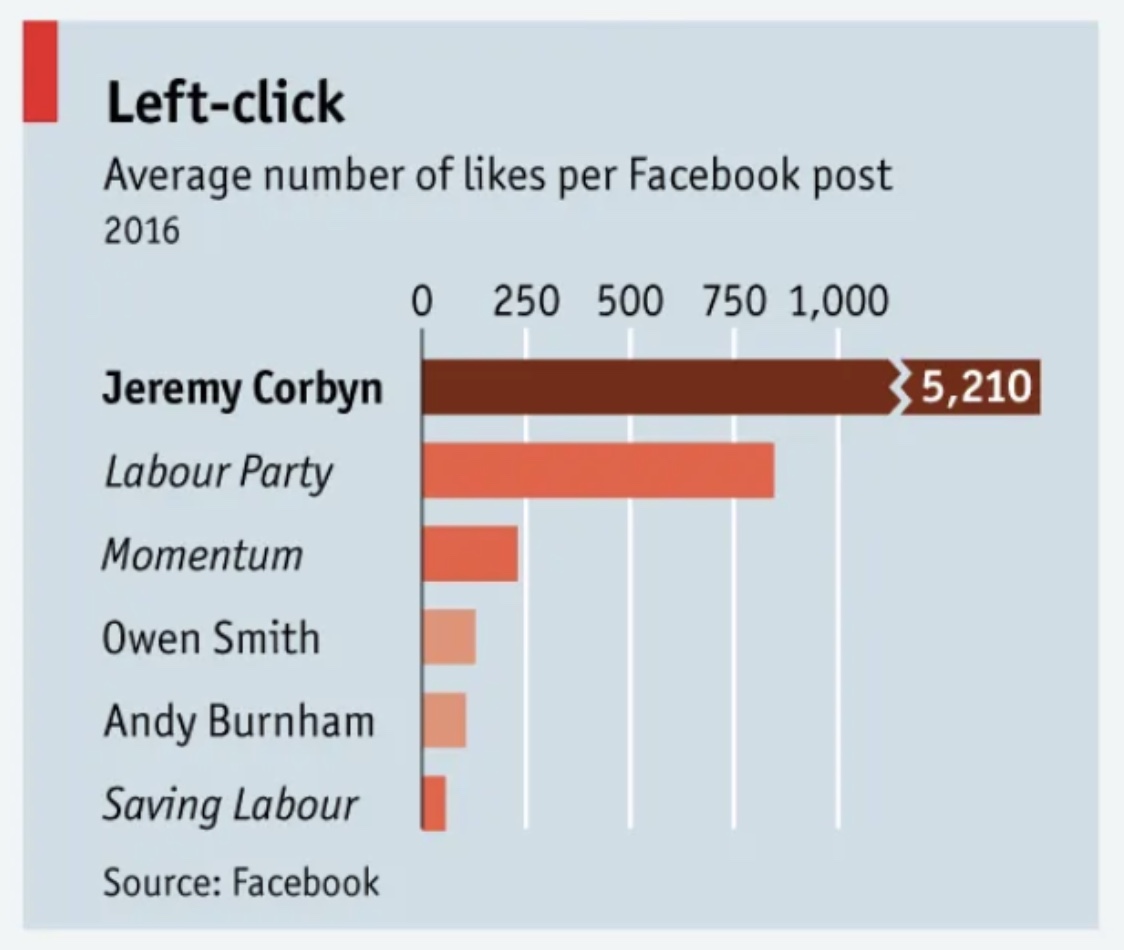
Version 2: Replicated Chart
Version 3: Improved Chart
This improved version starts the axis at zero with consistent scaling, making the dramatic difference visible: Jeremy Corbyn's engagement was more than 7 times higher than the Labour Party's. A single color scheme replaces the original's unexplained multiple colors, which added confusion rather than clarity.